
I gave a topic "International Spreadsheet Format Standard Implementation in Go Language" at Beijing Gopher Meetup on November 30th, 2019.
Excelize is a library written in pure Go providing a set of functions that allow you to write to and read from XLSX files, based on ECMA-376, ISO/IEC 29500 international spreadsheet document format standard. Supports reading and writing XLSX files generated by Microsoft Excel™ 2007 and later. This lecture will explore the international file format standards and interpret the use of Go XLSX documents. Excelize can be used in various reporting systems, rewards as the most valuable open source project in Open Source China in 2018, and is now the most popular spreadsheet document base for the Go language. This presentation will explore international document format standards, introducing the story to create this library, and share practices of implement international spreadsheet document format standards in the Go language.
The following is a summary of the content of the talk.
Prologue
Good afternoon, my name is Ri Xu. I'll talk about international spreadsheet format standard implementation in the Go language today. Everyone is familiar with spreadsheets. The classic spreadsheets represented by Excel applications have been used in various industries. According to estimates from relevant research institutions, the number of Office documents in the world reached 40 billion in 2007, and it grows at a scale of billions of years each year.
Why use Excelize
The spreadsheet documents as an important carrier of data that have been used in many fields, As a developer, in some cases, we need to manipulate Excel documents through programs, such as: open to read existing Excel document content, create new Excel documents, generate new Excel documents based on existing documents (templates), insert images into Excel documents, charts Elements such as tables and sometimes need to implement these operations across platforms. Excelize can easily meet these needs. Today's topic consists of two parts. The first part introduces the contents of the international spreadsheet document format standard, and the second part shares some experiences in the process of implementing the standard using the Go language.
International Office Document Format Standard
If you want to manipulate a spreadsheet document programmatically, you first need to understand its standards. ECMA-376, ISO/IEC 29500 as the international document format standard is a document format based on XML and ZIP technology, corresponding to familiar Office document files. The name of this standard involves three international standardization organizations: ECMA (European Computer Manufacturers Association), ISO (International Organization for Standardization), and IEC (International Electrotechnical Association). These international organizations have jointly developed international standards for document formats.
The standard features are divided into 6 aspects. There are some of the more representative features following:
- Interoperability - developers can write applications on multiple platforms that consume and produce Office Open XML.
- Internationalization - Office Open XML supports internationalization features required by such diverse languages as Arabic, Chinese (three variants), French, Hebrew, Hindi, Japanese, Korean, Russian, and Turkish. Office Open XML inherently supports Unicode because it is XML. In addition, Office Open XML has a rich set of internationalization features that have been refined over the course of many years. This list is representative.
- High fidelity migration - Office Open XML is designed to support all of the features in the Microsoft Office 97-2003 binary formats. It is difficult to overstate the difficulty of accomplishing this goal, and the consequent uniqueness of Office Open XML in doing so. Some formats, such as PDF, are designed to deliver a visual facsimile of a finished document to an end-user. In contrast, Office Open XML is intended to permit future editing or manipulation at the same level of abstraction available to the original creator; for example, reducing a vector graphic to a bitmap would fall short of this intent, as would collapsing a style hierarchy to independent styles. Further, a document can contain computational semantics that the original creator expects to preserve, such as formula logic that depends on intermediate calculation results, including error codes or animation rules that produce dynamic behavior.
- Low barrier to developer adoption, a developer can begin to write simple Office Open XML conforming applications within a few hours of beginning to read the Specification.
- Intergration with business data scalable - Office Open XML enables organizations to integrate productivity applications with information systems that manage business processes. It does so through the use of custom schemas within Office Open XML documents. The goal is to reuse and to automate the processing of business information that is otherwise buried opaquely inside documents, where business applications cannot read or write it.
This latest version of the standard is the 5th edition and consists of five parts. The first part of the 5th edition is a 5039 pages document. Standard specification files can be downloaded from the ISO or ECMA website. Foremost, the interoperability of Office Open XML has been accomplished through extensive contributions, modifications, and review of the specification by members of the ECMA TC45 committee with diverse backgrounds and corporate interests. Representation included some well-known vendors, corporations and organizations: Apple, Intel, Microsoft, BP, Essilor, The British Library and the United States Library of Congress, etc.
Some familiar applications such as Microsoft Office Excel, Apple Numbers, LibreOffice, Google Docs, Apache OpenOffice, etc., are typical representatives who follow this standard.
Standard specification

A primary objective of this white paper is to enable the reader to follow the high-level structure of any Office Open XML file. To accomplish this, we provide a moderate level of detail regarding the Open Packaging Conventions (OPC), and less detail regarding the individual markup languages. The markup language corresponding to a Word document is called WordprocessingML, the spreadsheet is SpreadsheetML, and the PowerPoint presentation corresponds to PresentationML. Excelize mainly implements SpreadsheetML. In addition, Office documents support nesting across applications. For example, Word can nest Excel, and Excel can nest Word. DrawingML markup is a cross-application text markup language that involves visual charts, extensible markup, source data, and directory references. An Office Open XML file is conventionally stored as a ZIP archive for purposes of packaging and compression, following the recommended implementation of the Open Packaging Conventions.
XSD (XML Schema Definition)
In order to make it easier for everyone to understand what follows content, I'll introduce a technical term named "XSD" here.
XSD (XML Schema Definition) is a World Wide Web Consortium (W3C) recommendation that specifies how to formally describe the elements in an Extensible Markup Language (XML) document.
There are sample example with employee element in the following structure:
<employee>
<firstname>John</firstname>
<lastname>Smith</lastname>
</employee>
the above code definition in W3C XML Schema:
<xs:element name="employee">
<xs:complexType>
<xs:element name="firestname" type="xs:string"></xs:element>
<xs:element name="lastname" type="xs:string"></xs:element>
</complexType>
</xs:element>
The type (xs:string) is prefixed with the namespace prefix associated with XML Schema that indicates a predefined schema data type.
XML Schema Dependency
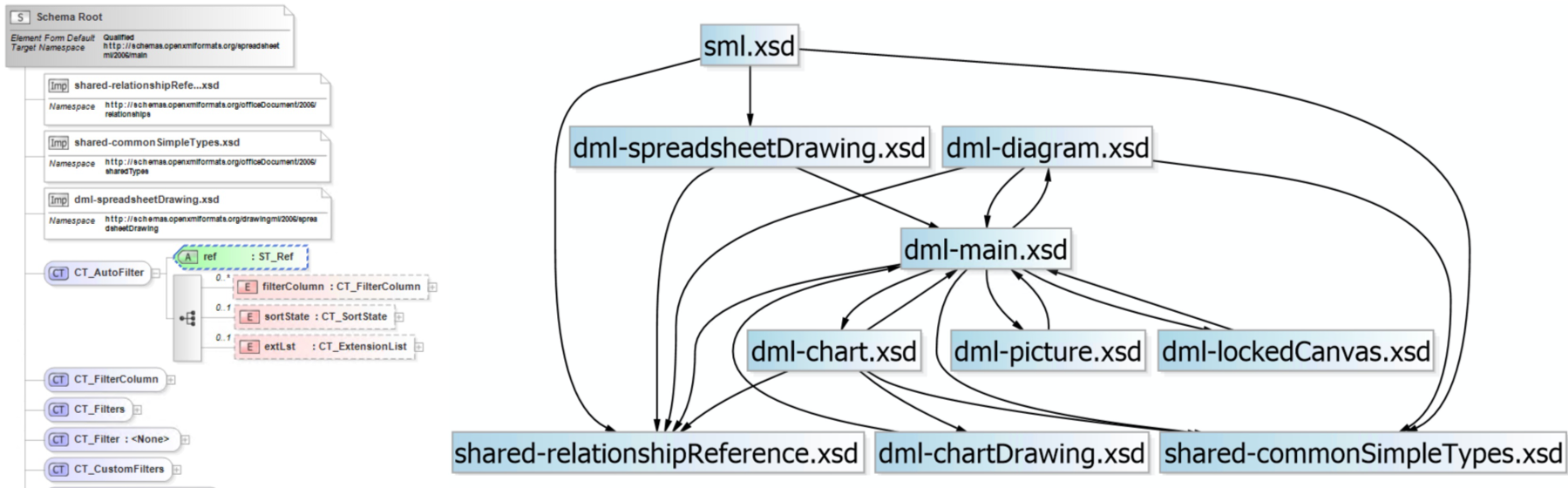
In the document format standard, the data structure is defined by XSD. After understanding the data structure definition, let's sort out the data structures involved in the spreadsheet document. This is a schematic diagram of the XML tags defined in an XSD file that formed the tree structure. XSDs can reference each other. Analyze and list the main data structure definition XSD file involved in the spreadsheet document, create a dependency graph like the right side, the root file is sml.xsd, which is the entry point used for the data structure definition of the spreadsheet document, and referenced some else common markup language data structures XSD files, such as the definitions for simple data types. The XSD files starting with dml- are DrawingML data structure definition files that cross-application visualization. The pictures, charts, graphics, and SmartArt are defined in those files. There are 7 XSD files related with DrawingML, and over 8,000 XML elements and attributes including in that. There are about thousands of element and attributes defined in sml.xsd. I using xgen tool to parsing and generate Go data struct definition code.
Format Interpretation
Let's take a look of XLSX file structure. For example Workbook1.xlsx:
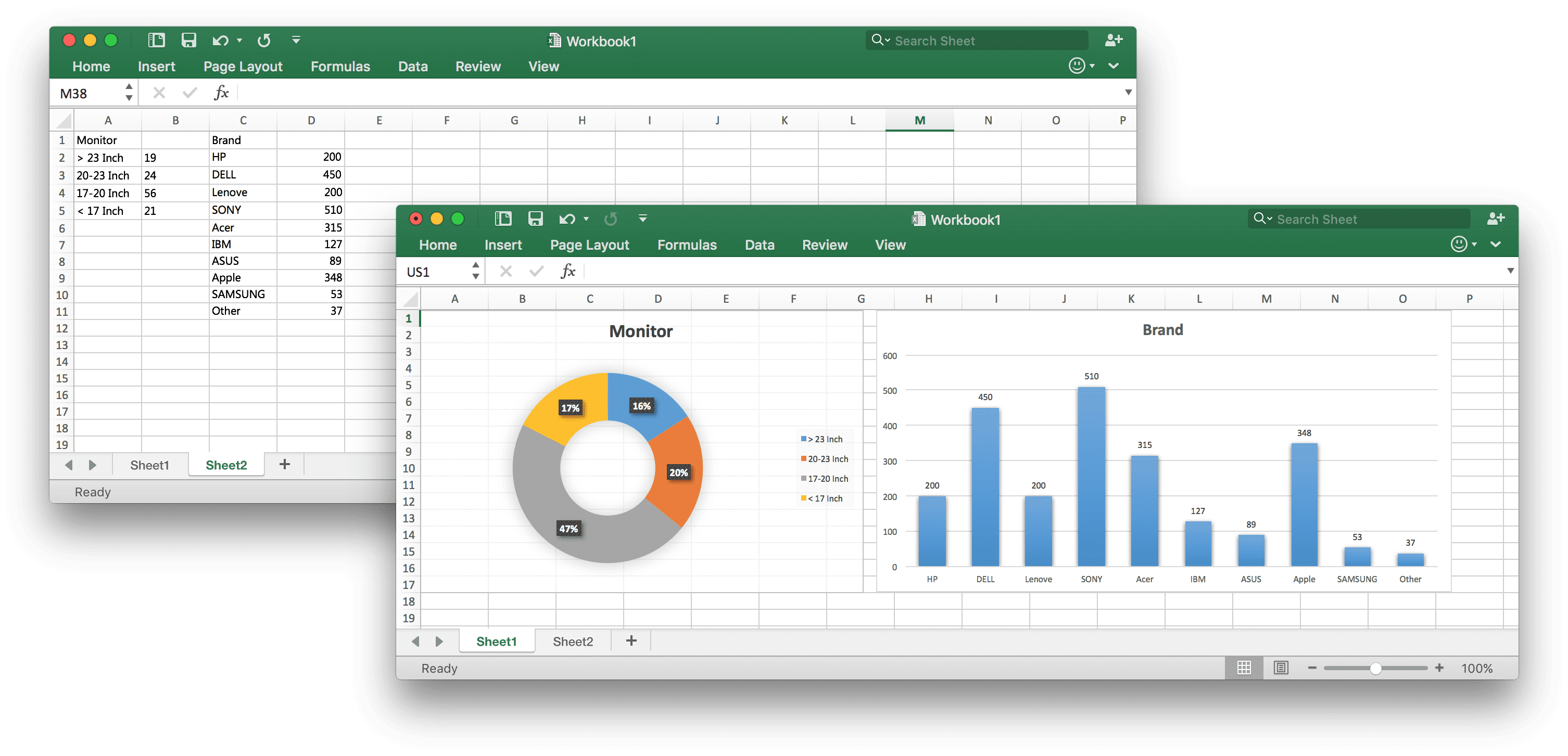
Unzip Workbook1.xlsx file we can got directory tree like this:
Workbook1
├── [Content_Types].xml
├── _rels
├── docProps
│ ├── app.xml
│ └── core.xml
└── xl
├── _rels
│ └── workbook.xml.rels
├── charts
│ ├── _rels
│ │ ├── chart1.xml.rels
│ │ └── chart2.xml.rels
│ ├── chart1.xml
│ ├── chart2.xml
│ ├── colors1.xml
│ ├── colors2.xml
│ ├── style1.xml
│ └── style2.xml
├── drawings
│ ├── _rels
│ │ └── drawing1.xml.rels
│ └── drawing1.xml
├── sharedStrings.xml
├── styles.xml
├── theme
│ └── theme1.xml
├── workbook.xml
└── worksheets
├── _rels
│ └── sheet1.xml.rels
├── sheet1.xml
└── sheet2.xml
Every package must have a [Content_Types].xml, found at the root of the package. This file contains a list of all of the content types of the parts in the package. Every part and its type must be listed in [Content_Types].xml. Every package contains the part of a relationship that defines the relationships between the other parts and to resources outside of the package. This separates the relationships from content and makes it easy to change relationships without changing the sources that reference targets. For an OOXML package, there is always a relationship part .rels within the _rels folder that identifies the starting parts of the package, or the package relationships. The worksheets directory contains all the data, formulas, and characteristics of a given worksheet.
Typical Workbook Scenario

A typical workbook will not be a blank, minimum workbook. A typical workbook might contain numbers, text, charts, tables, and pivot tables. Each of these additional parts is contained within the .zip package of the spreadsheet document.
XML Structure and Dependency Processing
Let's take a look about how cell D2 formatting. Cell D2 contains the text "Q1" and is defined in the cell table of sheet1. On this cell, the attribute value s="7" indicates that the 7th (zero-based) <xf> definition of
<xf> of <cellXfs> is defined.
The number formatting information cannot be found in a <numFmt> definition because it is a built-in format; instead, it is implicitly understood to be the 0th built-in number format. Remembering that the indexes to other element collections are also zero-based, the font information can be found in the 4th <font> definition; the fill information in the 2nd <fill> definition; and the border information in the 2nd <border> definition. The cell uses a cell style which is defined in the 1st <cellStyleXf> definition and, finally, borders specified in this master formatting record should be applied. Remember that these collections are zero-based. Additionally the <fill> definition for D2 references a themed color, whose index is 4th in the <clrScheme> definition of the theme part.
Graphically, the index references can be shown like this:

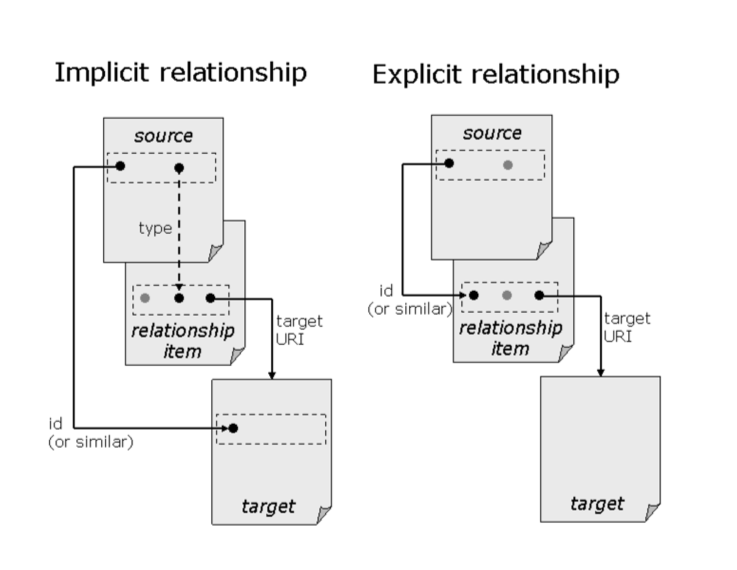
In OPC, relationships describe references from parts to other internal resources in the package or to external resources. They represent the type of connection between a source part and a target resource, and make the connection directly discoverable without looking at the part contents, so they are quick to resolve. The same ZIP item can be the target of multiple relationships. Office Open XML imposes constraints on relationships, described in subsequent clauses of this Part of ECMA-376. Relationships in Office Open XML are either explicit or implicit.
The following figure shows how the source, relationship item, and the target relate to each other for implicit and explicit relationships, respectively. The target does not have to be a file, however.
The Go Language Implementation
Next, I'll share some experiences about the implementation of this standard with the Go language.

The technical capabilities of Excelize can be divided into basic capabilities, style processing capabilities, data processing capabilities, pictures/charts, workbooks/worksheets, cells and model processing, 7 major parts:
- File Process Units: File Format Processor, Meta Processor, Embeddings Media, OPC Processor, Markup Language parsing
- Style Process Units: Border Processor, Freeze Panes, Fonts, Hight and Width, Number Format, Color System
- Runtime Model: Model Componments, Validator, Calculation Engine, Upgrade capabilities, Code Generator
- Chart and Picture Process Units: 2D/3D processing, Cluster/Stack/Area, Bar/Cone/Pie, Bubble/Scatter/Line, Combo Chart and Property Settings
- Workbook and Worksheet Process Units: Visibility, Row/Column Handler, Workbook and Worksheet Property Settings, Header/Footer, View Properties, Search Engine, Data Protection, Page Layout
- Cell Process Units: Data Types, Map, Merge Range, Rich Text, Hyperlink, Comments, Formula, Style Index, Cell Style
- Data Process Units: Data Validation, Time Processor, Crypto Class, Unit Converter, Table/Filter, Pivot Table, Conditional Format, VBA Script
Some third-party open-source spreadsheet libraries to manipulate slightly more complicated forms. In some cases, we have got a corrupted file after saving. To resolve this issue, Excelize needs to do a lot of compatibilities checks.
Excelize supports the generation over 52 categories charts for data visualization, it supports the creation of 2D and 3D charts, such as histograms, area charts, and stacked charts. Some kinds of charts belong to the same category. Design a skeleton that creates a basic structure, adjusts its specific parameters to change the type of chart. This method has been applied to creating cluster and stack charts, cluster and stack charts, etc.
Document Structure Definition
The File structure in the Excelize is used to define the document model, which includes exportable and non-exportable fields:
// File define a populated XLSX file struct.
type File struct {
checked map[string]bool
sheetMap map[string]string
CalcChain *xlsxCalcChain
Comments map[string]*xlsxComments
ContentTypes *xlsxTypes
Drawings map[string]*xlsxWsDr
Path string
SharedStrings *xlsxSST
Sheet map[string]*xlsxWorksheet
SheetCount int
Styles *xlsxStyleSheet
Theme *xlsxTheme
DecodeVMLDrawing map[string]*decodeVmlDrawing
VMLDrawing map[string]*vmlDrawing
WorkBook *xlsxWorkbook
Relationships map[string]*xlsxRelationships
XLSX map[string][]byte
CharsetReader charsetTranscoderFn
}
Exportable fields include worksheets, styles, reference relationships between data structures, etc, and developers can access them from the external. After opening a spreadsheet document with the Excelize, Excelize maintains dependencies between internal data structures through non-exportable fields. During the process of operation the spreadsheet, Excelize will perform dynamic memory adjustment and error correction at runtime. According to the design principle of on-demand processing, when the external API is called, Excelize can accurately identify which data structures to operate, load the required document data structure to the corresponding model as needed, and then process it through the internal processor. This processing design can improve the performance of file processing while ensuring compatibility.
Working with Excelize
Create XLSX file:
package main
import (
"fmt"
"github.com/xuri/excelize/v2"
)
func main() {
f := excelize.NewFile()
// Create a new sheet.
index := f.NewSheet("Sheet2")
// Set value of a cell.
f.SetCellValue("Sheet2", "A2", "Hello world.")
f.SetCellValue("Sheet1", "B2", 100)
// Set active sheet of the workbook.
f.SetActiveSheet(index)
// Save xlsx file by the given path.
if err := f.SaveAs("Book1.xlsx"); err != nil {
fmt.Println(err)
}
}
When I designing this library, I considered the developers of some other programming languages in the way of using it, hoping to reduce the learning cost of the developers and to achieve quickly start through simple and easy to use functions. The above is a minimal example usage that will create a XLSX file. Use the function NewFile to create a new Excel workbook. The newly created workbook contains a default worksheet named Sheet1. In order to generate a spreadsheet that contains a relatively large amount of data, Excelize also provides coordinates convert function, which supports conversion to corresponding coordinates during the iteration cycle.
Add picture to XLSX file:
package main
import (
"fmt"
_ "image/png"
"github.com/xuri/excelize/v2"
)
func main() {
f, err := excelize.OpenFile("Book1.xlsx")
if err != nil {
fmt.Println(err)
return
}
// Insert a picture.
if err := f.AddPicture("Sheet1", "A2", "image.png", ""); err != nil {
fmt.Println(err)
}
// Save the xlsx file with the origin path.
if err = f.Save(); err != nil {
fmt.Println(err)
}
}
We need to process more data structure, ensure compatibility when creating a picture or chart to the spreadsheet document. Which will be more complex to implement. AddPicture provides the method to add a picture in a sheet by given picture format set (such as offset, scale, aspect ratio setting and print settings) and file path. In addition, GetPicture provides a function to get picture base name and raw content embed in XLSX by given worksheet and cell name. This function returns the file name in XLSX and file contents as []byte data types.
Pivot Table
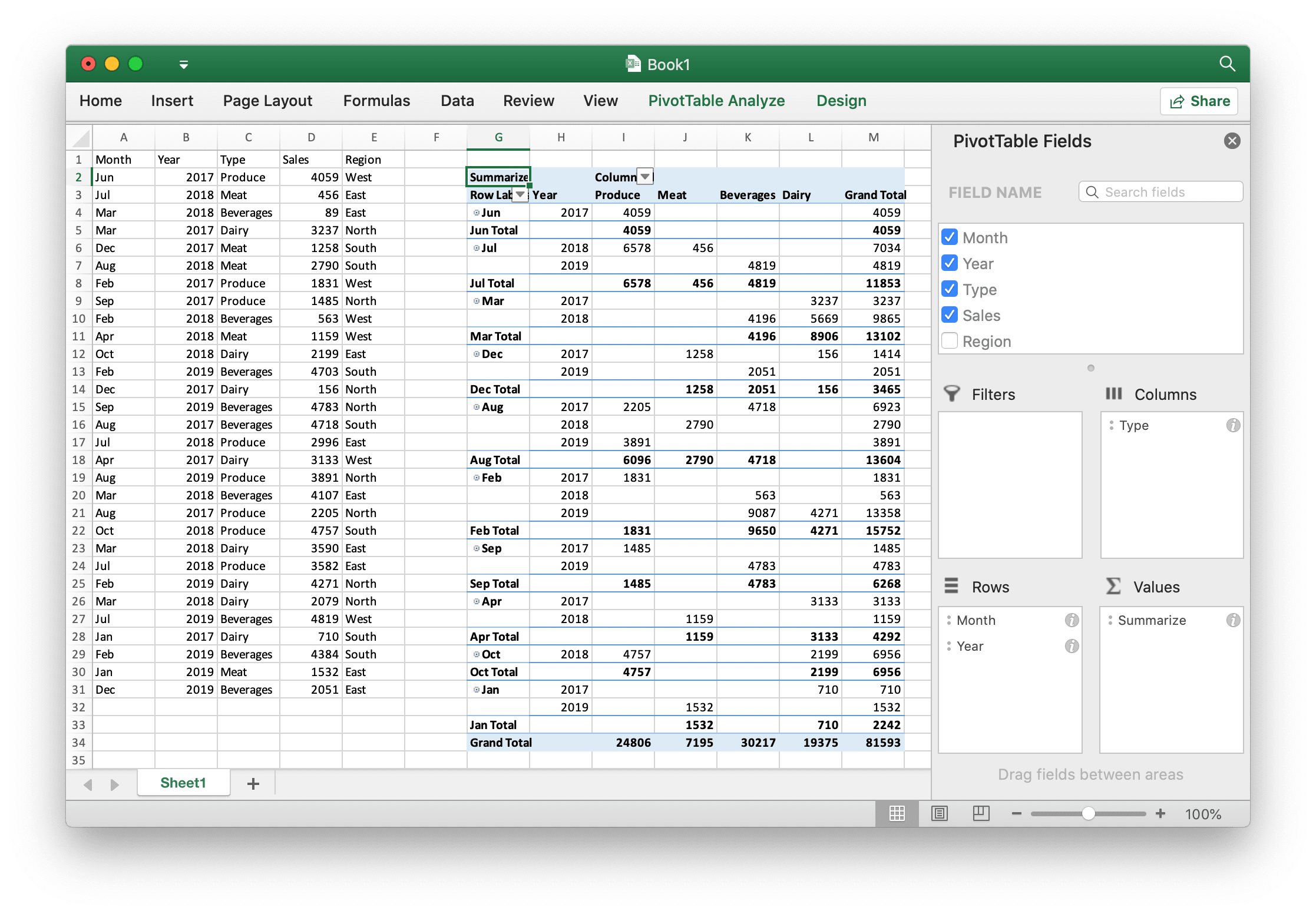
A pivot table is a table of statistics that summarizes the data of a more extensive table (such as from a database, spreadsheet, or business intelligence program). This summary might include sums, averages, or other statistics, which the pivot table groups together in a meaningful way. The example above includes 5 columns of data, including the Year, Month, Product Category, Product Sales, and Product Sales Area. If we need a summary of monthly sales by region, one-time filtering using traditional condition filtering is not possible, but we can use the pivot table to solve this problem:
err := f.AddPivotTable(&excelize.PivotTableOption{
DataRange: "Sheet1!$A$1:$E$31",
PivotTableRange: "Sheet1!$G$2:$M$34",
Rows: []excelize.PivotTableField{{Data: "Month"}, {Data: "Year"}},
Columns: []excelize.PivotTableField{{Data: "Type"}},
Data: []excelize.PivotTableField{{Data: "Sales", Name: "Summarize", Subtotal: "Sum"}},
})
The AddPivotTable provides the method to add pivot table by given pivot table options. DataSubtotal specifies the aggregation function that applies to this data field.
Runtime Model
Adjustment of the runtime model, let's imagine a scenario when the user opens an Excel document with 10,000 rows of data, then delete the 10th row after opening. In this case, many range related data objects will be affected, such as all cell data below 10th row, pictures with hyperlinks, pivot tables, filters and so on. Excelize will recalculate and adjust all rows below 10th row, and do real-time adjustment in runtime. Excelize has a method named adjustHelper that provides four parameters: sheet, adjustDirection, num and offset. There are series of functions in the adjustHelper, each sub-function will dynamic adjustment for spreadsheet components.
Performance
The following graph shows performance comparison of generation 12800*50 plain text matrix by the major open-source Excel libs under personal computer (2.6 GHz 6-Core Intel Core i7, 16 GB 2667 MHz DDR4, 500GB SSD, macOS Big Sur 11.6), including Go, Python, Java, PHP, and NodeJS.

Conclusion
Summarizing today's topic, I introduced the international spreadsheet document format standard firest and shared the practice of implementing the standard using the Go language, which involved the implementation of a series of core functions. Excelize's open-source wanna make better for the Go language ecosystem, hoping to help more friends in need. The roadmap of Excelize's includes formula calculation engine, VBA script and more complex chart operation support and continuous optimization of performance. Welcome every developer to participate in the open-source ecosystem by submitting issues, PR, donate, and other forms.
Q&A
Q: How about post-performance optimization and concurrency?
A: In the large-scale data search scenario, you can use the advantages of the Go language to search the worksheet content through multiple coroutines to improve the search speed. In addition, the Excelize also supports streaming reading and writing of large spreadsheets, which can save time and memory costs.