Hybla
Hybla aims to eliminate penalization of TCP connections that incorporate a high-latency terrestrial or satellite radio link, due to their longer round-trip times. It stems from an analytical evaluation of the congestion window dynamics, which suggests the necessary modifications to remove the performance dependence on RTT.
Hybla scales the window increment rule to ensure fairness among the flows with different RTTs. Hybla behaves as TCP NewReno when the RTT of a flow is less than a certain reference RTT(e.g. 25ms). Otherwise, TCP Hybla increases the congestion window size more aggressively to compensate throughput drop due to RTT increase.
Main algorithm:
Equalize performance for connections with different RTTs.
CWnd increase:
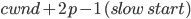
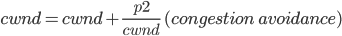
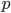 is a normalized
is a normalized 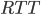 :
:
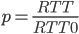
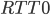 is in Linux set to 25ms.
is in Linux set to 25ms.
Designed for connections with long RTTs.
CUBIC
The protocol modifies the linear window growth function of existing TCP standards to be a cubic function in order to improve the scalability of TCP over fast and long distance networks. It also achieves more equitable bandwith allocations among flows with different RTTs by making the window growth to be independent of RTT, thus those flows grow their congestion window at the same rate.
During steady state, CUBIC increases the window size aggresively when the window is far from the saturation point, and the slowly when it is close to the saturation point.
Because it stays longer near the previous saturation point than other variants, it can be sluggish to find the new saturation point if the saturation point has increased far beyond the last one.
The key feature of CUBIC is that its window growth depends only on the real tiime between two consecutive congestion events. When RTTs are short, since the window growth rate is fixed, its growth rate could be slower than TCP standards.
This feature is not needed after entensive testing due to the increased stability of CUBIC. CUBIC replaced BIC-TCP as the default algorithm in 2006 after version 2.6.18.
NewReno
TCP New Reno, defined by RFC 6582 (which obsoletes previous definitions in RFC 3782 and RFC 2582), improves retransmission during the fast-recovery phase of TCP Reno. During fast recovery, for every duplicate ACK that is returned to TCP New Reno, a new unsent packet from the end of the congestion window is sent, to keep the transmit window full. For every ACK that makes partial progress in the sequence space, the sender assumes that the ACK points to a new hole, and the next packet beyond the ACKed sequence number is sent.
Because the timeout timer is reset whenever there is progress in the transmit buffer, this allows New Reno to fill large holes, or multiple holes, in the sequence space – much like TCP SACK. Because New Reno can send new packets at the end of the congestion window during fast recovery, high throughput is maintained during the hole-filling process, even when there are multiple holes, of multiple packets each. When TCP enters fast recovery it records the highest outstanding unacknowledged packet sequence number. When this sequence number is acknowledged, TCP returns to the congestion avoidance state.
A problem occurs with New Reno when there are no packet losses but instead, packets are reordered by more than 3 packet sequence numbers. When this happens, New Reno mistakenly enters fast recovery, but when the reordered packet is delivered, ACK sequence-number progress occurs and from there until the end of fast recovery, every bit of sequence-number progress produces a duplicate and needless retransmission that is immediately ACKed.
New Reno performs as well as SACK at low packet error rates, and substantially outperforms Reno at high error rates.
BBR
Google contributed BBR ("Bottleneck Bandwidth and RTT"), a new congestion control algorithm, to the the Linux kernel TCP stack. The commit description in the Linux TCP BBR commit describes the background, motivation, design, and example performance results for BBR.
Note that BBR require Linux Kernel verion 4.9 or later. Check kernel with command uname -r, add modify kernel parameters in /etc/sysctl.conf:
net.core.default_qdisc=fq net.ipv4.tcp_congestion_control=bbr
Save and take modify effect with command sudo sysctl -p, check configuration:
$ sysctl net.ipv4.tcp_available_congestion_control $ sysctl net.ipv4.tcp_congestion_control
Configure kernel modules to load at boot by add tcp_bbr in the file /etc/modules-load.d/modules.conf.
Optimization of algorithms between different regions:
| Bandwidth | Delay | Loss Tolerance | Recommended Algorithm | Example Network |
|---|---|---|---|---|
| High | Low | Low | Hybla | America - Asia |
| High | High | Low | BBR | America - Europ |
| High or Low | High or Low | High | CUBIC | Asia - Asia |
Reference
Injong Rhee, and Lisong Xu: CUBIC: A New TCP-Friendly High-Speed TCP Variant
TCP Hybla: a TCP enhancement for heterogeneous networks
BBR: Congestion-Based Congestion Control
Neal Cardwell, Yuchung Cheng,C. Stephen Gunn, Soheil Hassas Yeganeh, Van Jacobson: BBR Congestion Control