![]()
Introduction
Apache Spark is a fast and general engine for large-scale data processing. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation that has maintained it since. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
Environment Versions
Ubuntu Server 14.04.4 LTS (Trusty Tahr) 64-bit Docker 1.10.3 Hadoop 2.6.0 Spark 1.6.0
Install Docker
Update package information, ensure that APT works with the https method, and that CA certificates are installed.
$ apt-get update $ apt-get install apt-transport-https ca-certificates
Add the new GPG key.
$ sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
Open the /etc/apt/sources.list.d/docker.list file in your favorite editor.
If the file doesn't exist, create it.
Remove any existing entries.
Add an entry for your Ubuntu operating system.
deb https://apt.dockerproject.org/repo ubuntu-trusty main
Save and close the /etc/apt/sources.list.d/docker.list file.
Update the APT package index and install Docker:
$ sudo apt-get update && sudo apt-get install docker-engine
Running docker without sudo
$ sudo gpasswd -a ${USER} docker
Restart the docker daemon.
$ sudo service docker restart
Verify docker is installed correctly.
$ docker run hello-world
Pull Spark Images
Docker pull Spark image from Docker Hub:
$ docker pull sequenceiq/spark:1.6.0
Create Container
We will build a multi-node cluster in which one is master and the other is slaves1 and slave2, create three continers in different terminal.
Create master:
$ docker run --name master -it -p 8088:8088 -p 8042:8042 -p 8085:8080 -p 4040:4040 -p 7077:7077 -p 2022:22 -v /data:/data -h master sequenceiq/spark:1.6.0 bash
Create slaves:
$ docker run --name slave1 -it -h slave1 sequenceiq/spark:1.6.0 bash $ docker run --name slave2 -it -h slave2 sequenceiq/spark:1.6.0 bash
Hadoop Configuration
Stop the Hadoop multi-node cluster on all nodes:
# $HADOOP_COMMON_HOME/sbin/stop-dfs.sh && $HADOOP_COMMON_HOME/sbin/stop-yarn.sh
Update /etc/hosts on every nodes:
# vi /etc/hosts
Put the alias to the ip addresses of all the nodes:
172.17.0.2 master # IP address of the master node 172.17.0.3 slave1 # IP address of the slave2 node 172.17.0.4 slave2 # IP address of the slave2 node
Configuration Hadoop slaves file on all nodes:
# vi $HADOOP_CONF_DIR/slaves
slave1 slave2
Create name, data and tmp folder for Hadoop on all nodes:
# mkdir -pv $HADOOP_COMMON_HOME/dfs/name # mkdir -pv $HADOOP_COMMON_HOME/dfs/data # mkdir -pv $HADOOP_COMMON_HOME/tmp
Configuration Hadoop core-site.xml file on all nodes:
# vi $HADOOP_CONF_DIR/core-site.xml
Change sandbox to master and add a hadoop.tmp.dir property:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
Configuration Hadoop hdfs-site.xml file on all nodes:
$ vi $HADOOP_CONF_DIR/hdfs-site.xml
Set dfs.replication value from 1 to 3:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
Configuration Hadoop mapred-site.xml file on all nodes:
$ vi $HADOOP_CONF_DIR/mapred-site.xml
Change sandbox to master:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
Configuration Hadoop yarn-site.xml file on all nodes:
$ vi $HADOOP_CONF_DIR/yarn-site.xml
Change sandbox to master:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/*</value>
</property>
<property>
<description>
Number of seconds after an application finishes before the nodemanager's
DeletionService will delete the application's localized file directory
and log directory.
To diagnose Yarn application problems, set this property's value large
enough (for example, to 600 = 10 minutes) to permit examination of these
directories. After changing the property's value, you must restart the
nodemanager in order for it to have an effect.
The roots of Yarn applications' work directories is configurable with
the yarn.nodemanager.local-dirs property (see below), and the roots
of the Yarn applications' log directories is configurable with the
yarn.nodemanager.log-dirs property (see also below).
</description>
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>600</value>
</property>
</configuration>
Format NameNode on master node:
# hdfs namenode -format
Spark Configuration
Configuration Spark slaves file on all nodes:
# cp $SPARK_HOME/conf/slaves.template $SPARK_HOME/conf/slaves && vi $SPARK_HOME/conf/slaves
Add following lines in file:
slave1 slave2
Configuration Spark spark-env.sh file on all node:
# cp $SPARK_HOME/conf/spark-env.sh.template $SPARK_HOME/conf/spark-env.sh && vi $SPARK_HOME/conf/spark-env.sh
Add following lines in file:
export JAVA_HOME=/usr/java/default
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
Configuration Spark core-site.xml file on all nodes:
# vi $SPARK_HOME/yarn-remote-client/core-site.xml
Change sandbox to master:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>dfs.client.use.legacy.blockreader</name>
<value>true</value>
</property>
</configuration>
Configuration Spark yarn-site.xml file on all nodes:
# vi $SPARK_HOME/yarn-remote-client/yarn-site.xml
Change sandbox to master:
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/*, /usr/local/hadoop/share/spark/*</value>
</property>
</configuration>
Starting Hadoop multi-node cluster on master node:
# $HADOOP_COMMON_HOME/sbin/start-dfs.sh && $HADOOP_COMMON_HOME/sbin/start-yarn.sh
Track/Monitor/Verify Hadoop cluster on master node:
# jps 1650 SecondaryNameNode 2043 Jps 1484 NameNode 1789 ResourceManager
Track/Monitor/Verify Hadoop cluster on slaves nodes:
# jps 1343 DataNode 1434 NodeManager 1530 Jps
Start Apache Spark on msater node:
# $SPARK_HOME/sbin/start-all.sh
Track/Monitor/Verify Apache Spark cluster on master node:
# jps 2148 Jps 2084 Master 1650 SecondaryNameNode 1484 NameNode 1789 ResourceManage
Track/Monitor/Verify Apache Spark cluster on slaves nodes:
# jps 1733 Jps 1343 DataNode 1434 NodeManager
Monitor Hadoop ResourseManage and Hadoop NameNode via web-version ResourceManager http://master:8088, because I run Docker in Ubuntu server and Ubuntu Server IP address is 172.16.136.128, so I can also visit http://172.16.136.128:8088:
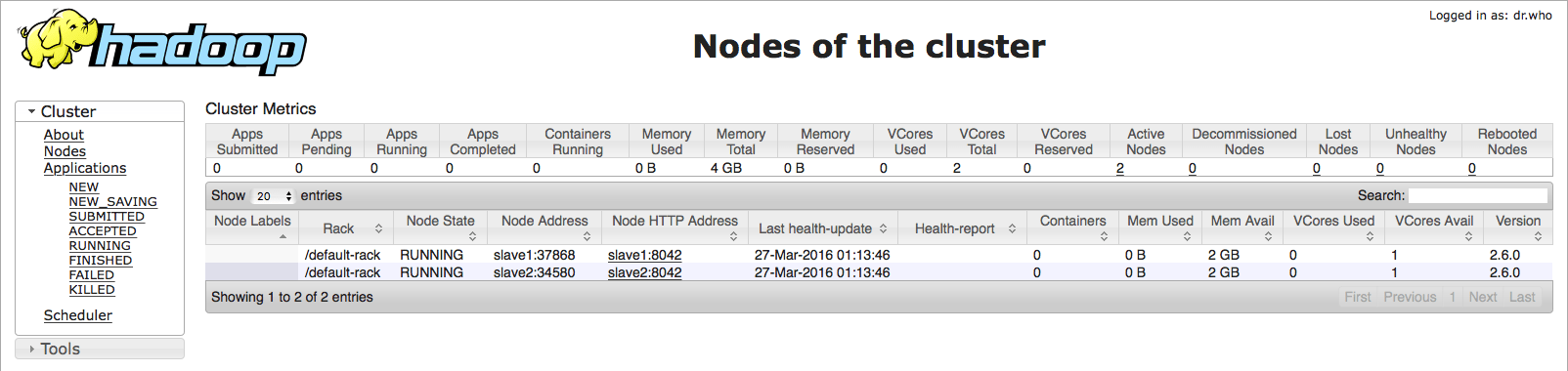
Apache Spark Web UI http://master:8080 and I can also visit http://172.16.136.128:8085:
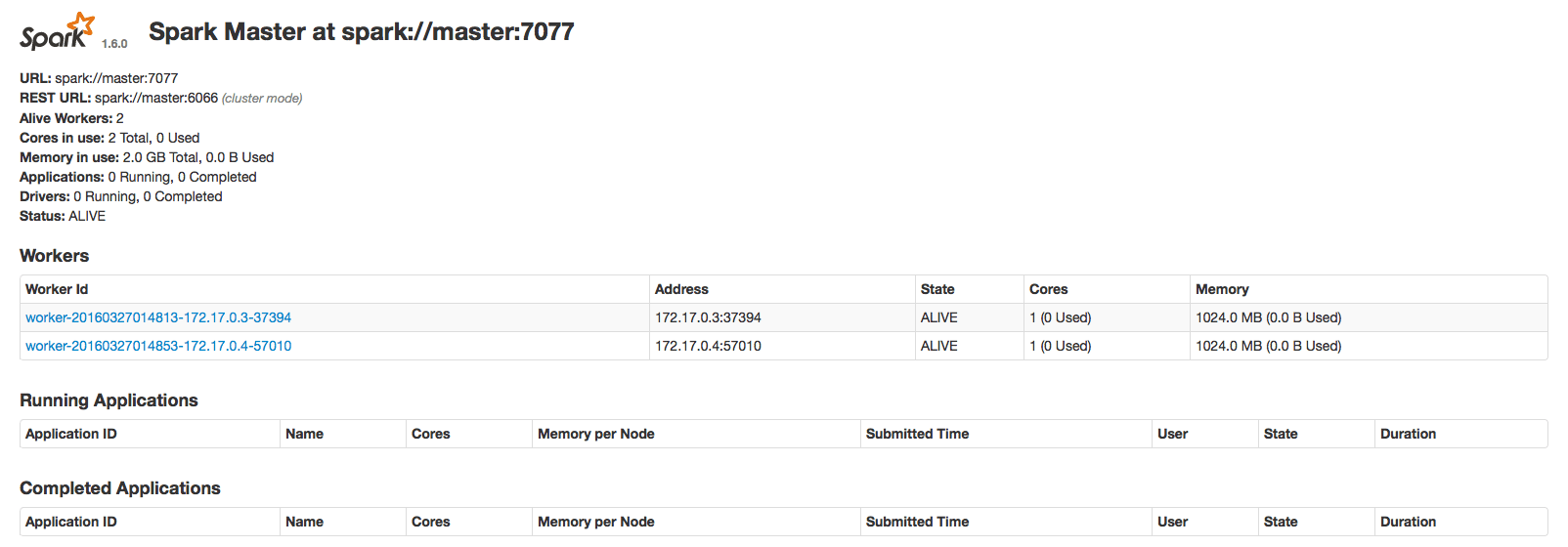
Issues
If got following error when start Apache Spark on msater node by $SPARK_HOME/sbin/start-all.sh command:
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out slave2: failed to launch org.apache.spark.deploy.worker.Worker: slave2: at java.lang.ClassLoader.loadClass(libgcj.so.10) slave2: at gnu.java.lang.MainThread.run(libgcj.so.10) slave2: full log in /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out slave1: failed to launch org.apache.spark.deploy.worker.Worker: slave1: at java.lang.ClassLoader.loadClass(libgcj.so.10) slave1: at gnu.java.lang.MainThread.run(libgcj.so.10) slave1: full log in /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out
Check OS Java version and list old version Java:
# echo $JAVA_HOME /usr/java/default # rpm -qa | grep java java_cup-0.10k-5.el6.x86_64 gcc-java-4.4.7-16.el6.x86_64 java-1.5.0-gcj-devel-1.5.0.0-29.1.el6.x86_64 R-java-devel-3.2.3-1.el6.x86_64 R-java-3.2.3-1.el6.x86_64 java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
List installed JDK:
# rpm -qa | grep jdk jdk-1.7.0_51-fcs.x86_64
Remove old version Java and JDK:
# rpm -e --nodeps java_cup-0.10k-5.el6.x86_64 # rpm -e --nodeps java-1.5.0-gcj-1.5.0.0-29.1.el6.x86_64
Related Articles
Hi! I followed the your steps and successfully see the hadoop and spark cluster. However when running "spark-shell --master yarn-client" I'm getting the following error:
java.io.FileNotFoundException: File does not exist: hdfs://master:9000/spark/spark-assembly-1.6.0-hadoop2.6.0.jar
Any idea how I can fix this?
I solved this error by copying the spark-assembly-1.6.0-hadoop2.6.0.jar to hdfs. But now all of my jobs are stuck in the accepted state by yarn.
You re a creazy mean bhro.... Thanks.... you easy my world... i will shared this!!!...Congrats..
i running with Docker in Windows... and this work